Scale
Deploying large scale applications, require a better understanding of infrastructure capabilities, in terms of resource availability, failure domains, scaling options like using anycast, layer 4/7 load balancer, DNS based load balancing.
Building large scale applications is a complex activity, which should cover many aspects in design, development and as well as operationalisation. This section will talk about the considerations to look for while deploying them.
Failure domains
In any infrastructure, failures due to hardware or software issues are common. Though these may be a pain from a service availability perspective, these failures do happen and a pragmatic goal would be to, try to keep these failures to the minimum. Hence while deploying any service, failures/non-availability of some of the nodes to be factored in.
Server failures
A server could fail, due to power or NIC or software bug. And at times it may not be a complete failure but could be an error in the NIC, which causes some packet loss. This is a very common scenario and will impact the stateful services more. While designing such services, it is important to accommodate some level of tolerance to such failures.
ToR failures
This is one of the common scenarios, where the leaf switch connecting the servers goes down, along with it taking down the entire cabinet. There could be more than one server of the same service that can go down in this case. It requires planning to decide how much server loss can be handled without overloading other servers. Based on this, the service can be distributed across many cabinets. These calculations may vary, depending upon the resiliency in the ToR design, which will be covered in ToR connectivity section.
Site failures
Here site failure is a generic term, which could mean, a particular service is down in a site, maybe due to new version rollout, or failures of devices like firewall, load balancer, if the service depends on them, or loss of connectivity to remote sites (which might have limited options for resiliency) or issues with critical services like DNS, etc. Though these events may not be common, they can have a significant impact.
In summary, handling these failure scenarios has to be thought about while designing the application itself. That will provide the tolerance required within the application to recover from unexpected failures. This will help not only for failures, even for planned maintenance work, as it will be easier to take part of the infrastructure, out of service.
Resource availability
The other aspect to consider while deploying applications at scale is the availability of the required infrastructure and the features the service is dependent upon. For example, for the resiliency of a cabinet, if one decides to distribute the service to 5 cabinets, but the service needs a load balancer (to distribute incoming connections to different servers), it may become challenging if load balancers are not supported in all cabinets. Or there could be a case that there are not enough cabinets available (that meet the minimum required specification for service to be set up). The best approach in these cases is to identify the requirements and gaps and then work with the Infrastructure team to best solve them.
Scaling options
While distributing the application to different cabinets, the incoming traffic to these services has to be distributed across these servers. To achieve this, the following may be considered
Anycast
This is one of the quickest ways to roll out traffic distribution across multiple cabinets. In this, each server, part of the cluster (where the service is set up), advertises a loopback address (/32 IPv4 or /128 IPv6 address), to the DC switch fabric (most commonly BGP is used for this purpose). The service has to be set up to be listening to this loopback address. When the clients try to connect to the service, get resolved to this virtual address and forward their queries. The DC switch fabric distributes each flow into different available next hops (eventually to all the servers in that service cluster).
Note: The DC switch computes a hash, based on the IP packet header, this could include any combination of source and destination addresses, source and destination port, mac address and IP protocol number. Based on this hash value, a particular next-hop is picked up. Since all the packets in a traffic flow, carry the same values for these headers, all the packets in that flow will be mapped to the same path.
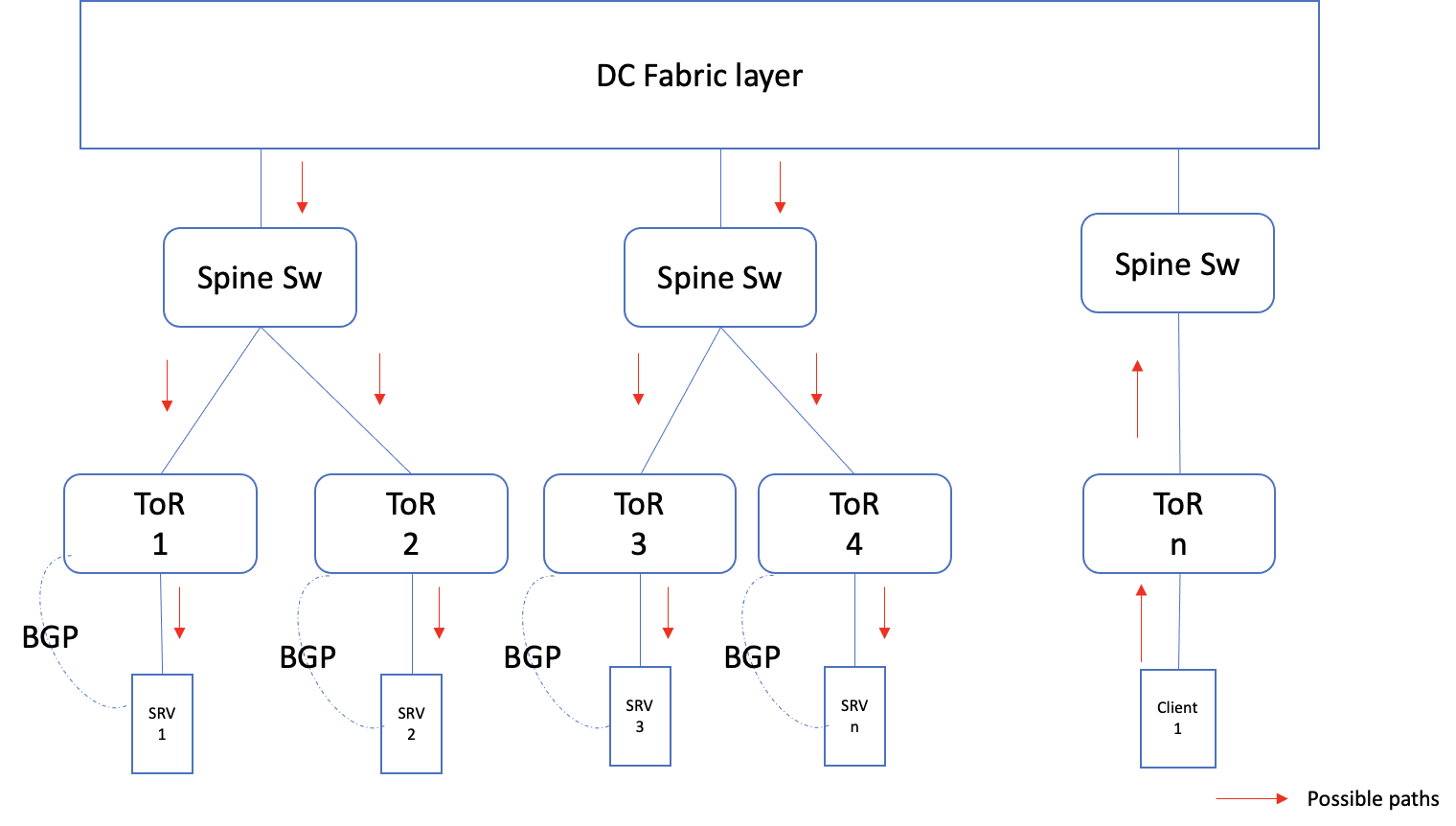
Fig 1: Anycast setup
To achieve a proportionate distribution of flows across these servers, it is important to maintain uniformity in each of the cabinets and pods. But remember, the distribution happens only based on flows, and if there are any elephant (large) flows, some servers might receive a higher volume of traffic.
If there are any server or ToR failures, the advertisement of loopback address to the switches will stop, and thereby the new packets will be forwarded to the remaining available servers.
Load balancer
Another common approach is to use a load balancer. A Virtual IP is set up in the load balancers, to which the client connects while trying to access the service. The load balancer, in turn, redirects these connections to, one of the actual servers, where the service is running. In order to, verify the server is in the serviceable state, the load balancer does periodic health checks, and if it fails, the LB stops redirecting the connection to these servers.
The load balancer can be deployed in single-arm mode, where the traffic to the VIP is redirected by the LB, and the return traffic from the server to the client is sent directly. The other option is the two-arm mode, where the return traffic is also passed through the LB.
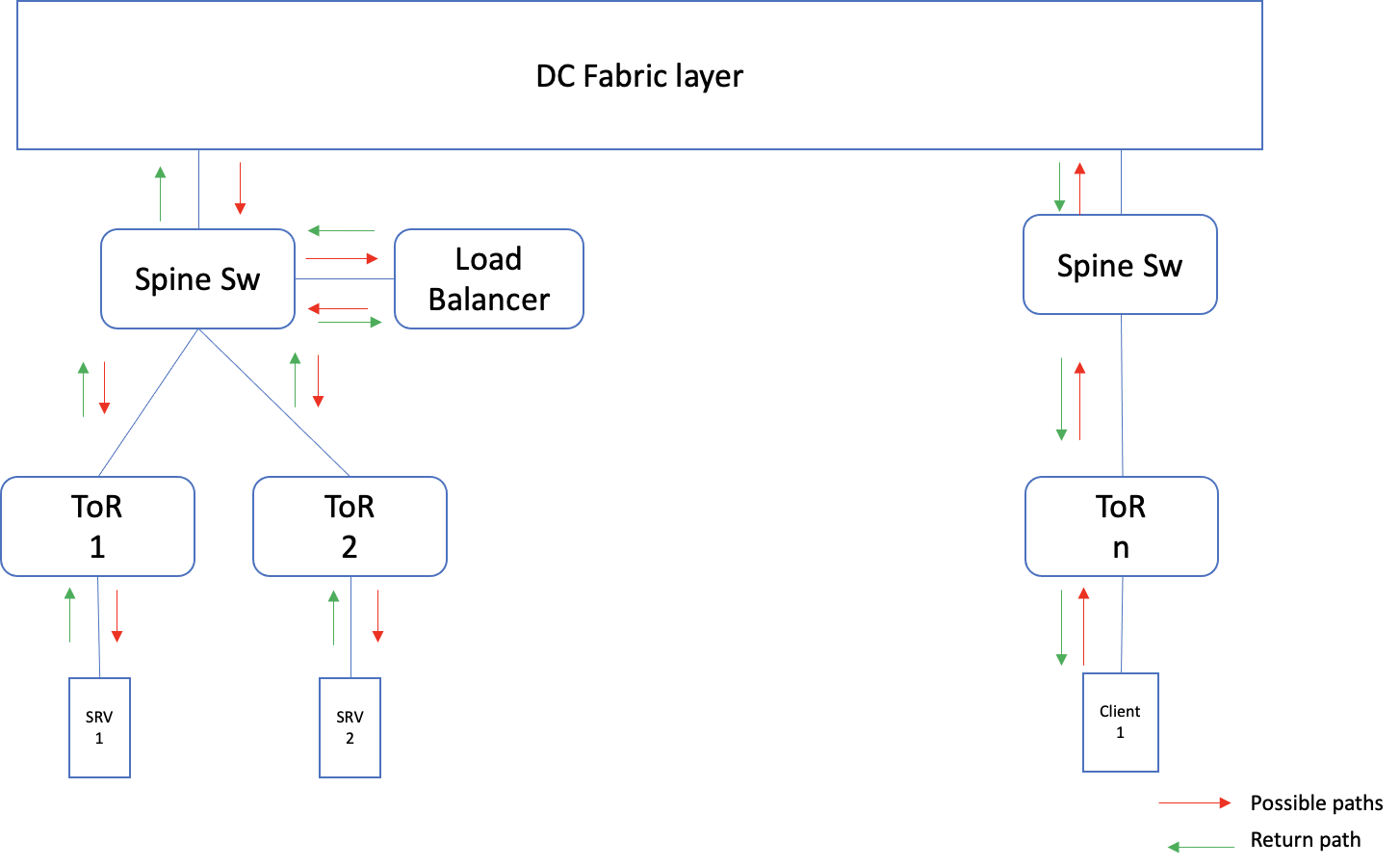
Fig 2: Single-arm mode
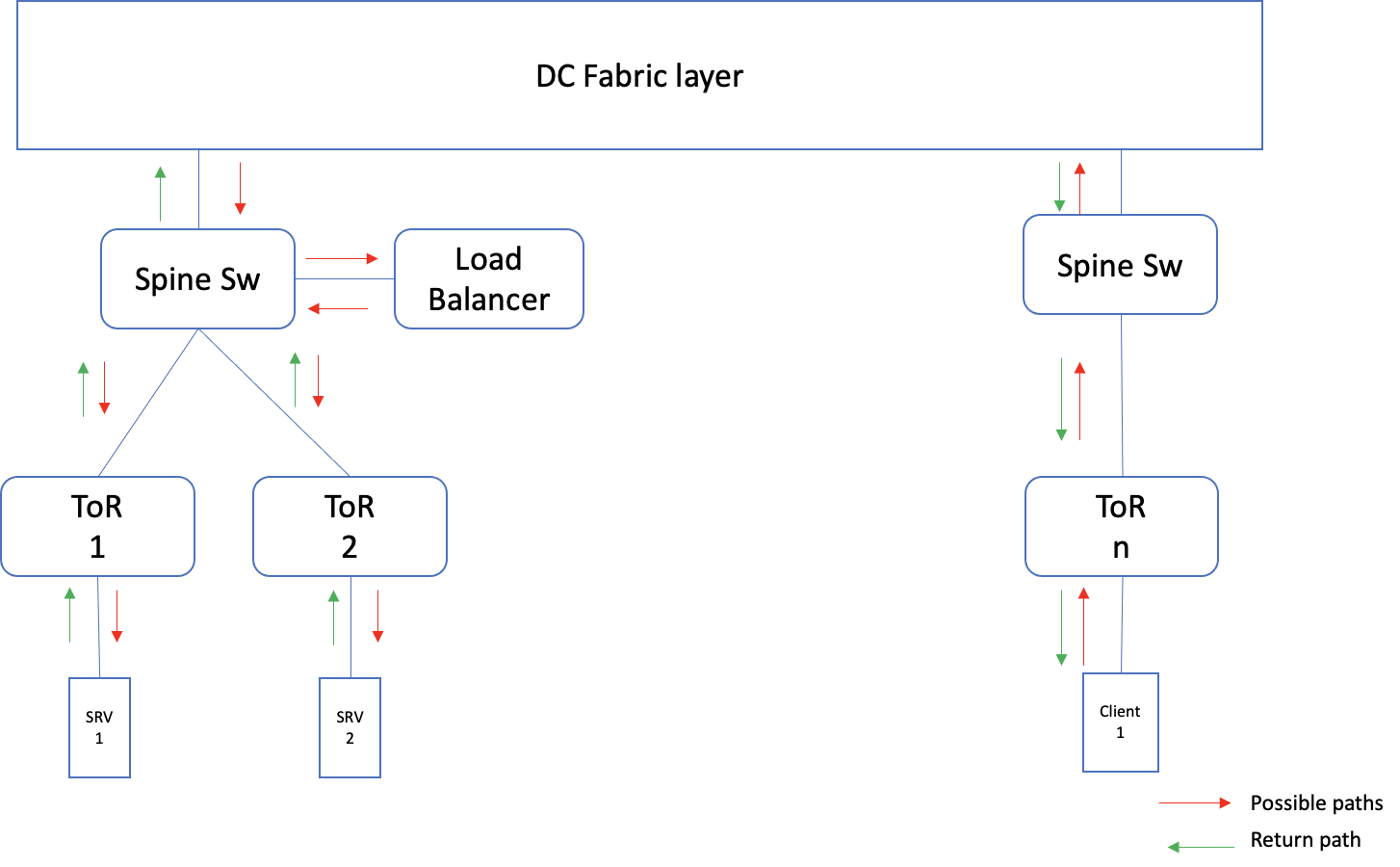
Fig 3: Two-arm mode
One of the cons of this approach is, at a higher scale, the load balancer can become the bottleneck, to support higher traffic volumes or concurrent connections per second.
DNS based load balancing
This is similar to the above approach, with the only difference is instead of an appliance, the load balancing is done at the DNS. The clients get different IP's to connect when they query for the DNS records of the service. The DNS server has to do a health check, to know which servers are in a good state.
This approach alleviates the bottleneck of the load balancer solution. But require shorter TTL for the DNS records, so that problematic servers can be taken out of rotation quickly, which means, there will be far more DNS queries.