Prerequisites
What to expect from this course
Monitoring is an integral part of any system. As an SRE, you need to have a basic understanding of monitoring a service infrastructure. By the end of this course, you will gain a better understanding of the following topics:
-
What is monitoring?
-
What needs to be measured
-
How the metrics gathered can be used to improve business decisions and overall reliability
-
Proactive monitoring with alerts
-
Log processing and its importance
-
-
What is observability?
-
Distributed tracing
-
Logs
-
Metrics
-
What is not covered in this course
-
Guide to setting up a monitoring infrastructure
-
Deep dive into different monitoring technologies and benchmarking or comparison of any tools
Course content
Introduction
Monitoring is a process of collecting real-time performance metrics from a system, analyzing the data to derive meaningful information, and displaying the data to the users. In simple terms, you measure various metrics regularly to understand the state of the system, including but not limited to, user requests, latency, and error rate. What gets measured, gets fixed—if you can measure something, you can reason about it, understand it, discuss it, and act upon it with confidence.
Four golden signals of monitoring
When setting up monitoring for a system, you need to decide what to measure. The four golden signals of monitoring provide a good understanding of service performance and lay a foundation for monitoring a system. These four golden signals are
-
Traffic
-
Latency
-
Error
-
Saturation
These metrics help you to understand the system performance and bottlenecks, and to create a better end-user experience. As discussed in the Google SRE book, if you can measure only four metrics of your service, focus on these four. Let's look at each of the four golden signals.
-
Traffic—Traffic gives a better understanding of the service demand. Often referred to as service QPS (queries per second), traffic is a measure of requests served by the service. This signal helps you to decide when a service needs to be scaled up to handle increasing customer demand and scaled down to be cost-effective.
-
Latency—Latency is the measure of time taken by the service to process the incoming request and send the response. Measuring service latency helps in the early detection of slow degradation of the service. Distinguishing between the latency of successful requests and the latency of failed requests is important. For example, an HTTP 5XX error triggered due to loss of connection to a database or other critical backend might be served very quickly. However, because an HTTP 500 error indicates a failed request, factoring 500s into overall latency might result in misleading calculations.
-
Error (rate)—Error is the measure of failed client requests. These failures can be easily identified based on the response codes (HTTP 5XX error). There might be cases where the response is considered erroneous due to wrong result data or due to policy violations. For example, you might get an HTTP 200 response, but the body has incomplete data, or response time is breaching the agreed-upon SLAs. Therefore, you need to have other mechanisms (code logic or instrumentation) in place to capture errors in addition to the response codes.
-
Saturation—Saturation is a measure of the resource utilization by a service. This signal tells you the state of service resources and how full they are. These resources include memory, compute, network I/O, and so on. Service performance slowly degrades even before resource utilization is at 100 percent. Therefore, having a utilization target is important. An increase in latency is a good indicator of saturation; measuring the 99th percentile of latency can help in the early detection of saturation.
Depending on the type of service, you can measure these signals in different ways. For example, you might measure queries per second served for a web server. In contrast, for a database server, transactions performed and database sessions created give you an idea about the traffic handled by the database server. With the help of additional code logic (monitoring libraries and instrumentation), you can measure these signals periodically and store them for future analysis. Although these metrics give you an idea about the performance at the service end, you need to also ensure that the same user experience is delivered at the client end. Therefore, you might need to monitor the service from outside the service infrastructure, which is discussed under third-party monitoring.
Why is monitoring important?
Monitoring plays a key role in the success of a service. As discussed earlier, monitoring provides performance insights for understanding service health. With access to historical data collected over time, you can build intelligent applications to address specific needs. Some of the key use cases follow:
-
Reduction in time to resolve issues—With a good monitoring infrastructure in place, you can identify issues quickly and resolve them, which reduces the impact caused by the issues.
-
Business decisions—Data collected over a period of time can help you make business decisions such as determining the product release cycle, which features to invest in, and geographical areas to focus on. Decisions based on long-term data can improve the overall product experience.
-
Resource planning—By analyzing historical data, you can forecast service compute-resource demands, and you can properly allocate resources. This allows financially effective decisions, with no compromise in end-user experience.
Before we dive deeper into monitoring, let's understand some basic terminologies.
-
Metric—A metric is a quantitative measure of a particular system attribute—for example, memory or CPU
-
Node or host—A physical server, virtual machine, or container where an application is running
-
QPS—Queries Per Second, a measure of traffic served by the service per second
-
Latency—The time interval between user action and the response from the server—for example, time spent after sending a query to a database before the first response bit is received
-
Error rate—Number of errors observed over a particular time period (usually a second)
-
Graph—In monitoring, a graph is a representation of one or more values of metrics collected over time
-
Dashboard—A dashboard is a collection of graphs that provide an overview of system health
-
Incident—An incident is an event that disrupts the normal operations of a system
-
MTTD—Mean Time To Detect is the time interval between the beginning of a service failure and the detection of such failure
-
MTTR—Mean Time To Resolve is the time spent to fix a service failure and bring the service back to its normal state
Before we discuss monitoring an application, let us look at the monitoring infrastructure. Following is an illustration of a basic monitoring system.
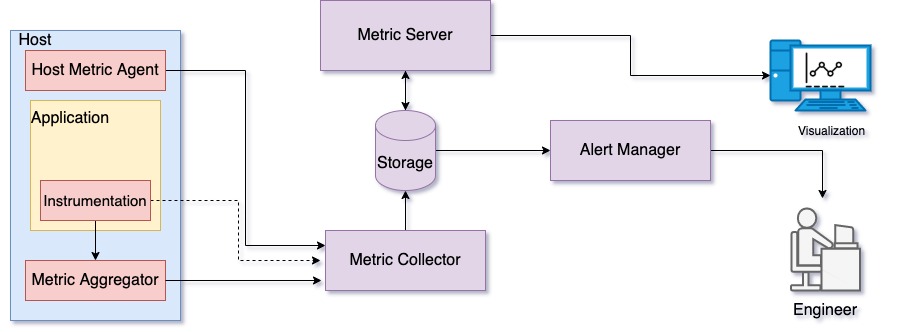
Figure 1: Illustration of a monitoring infrastructure
Figure 1 shows a monitoring infrastructure mechanism for aggregating metrics on the system, and collecting and storing the data for display. In addition, a monitoring infrastructure includes alert subsystems for notifying concerned parties during any abnormal behavior. Let's look at each of these infrastructure components:
-
Host metrics agent—A host metrics agent is a process running on the host that collects performance statistics for host subsystems such as memory, CPU, and network. These metrics are regularly relayed to a metrics collector for storage and visualization. Some examples are collectd, telegraf, and metricbeat.
-
Metric aggregator—A metric aggregator is a process running on the host. Applications running on the host collect service metrics using instrumentation. Collected metrics are sent either to the aggregator process or directly to the metrics collector over API, if available. Received metrics are aggregated periodically and relayed to the metrics collector in batches. An example is StatsD.
-
Metrics collector—A metrics collector process collects all the metrics from the metric aggregators running on multiple hosts. The collector takes care of decoding and stores this data on the database. Metric collection and storage might be taken care of by one single service such as InfluxDB, which we discuss next. An example is carbon daemons.
-
Storage—A time-series database stores all of these metrics. Examples are OpenTSDB, Whisper, and InfluxDB.
-
Metrics server—A metrics server can be as basic as a web server that graphically renders metric data. In addition, the metrics server provides aggregation functionalities and APIs for fetching metric data programmatically. Some examples are Grafana and Graphite-Web.
-
Alert manager—The alert manager regularly polls metric data available and, if there are any anomalies detected, notifies you. Each alert has a set of rules for identifying such anomalies. Today many metrics servers such as Grafana support alert management. We discuss alerting in detail later. Examples are Grafana and Icinga.