TCP
TCP is a transport layer protocol like UDP but it guarantees reliability, flow control and congestion control.
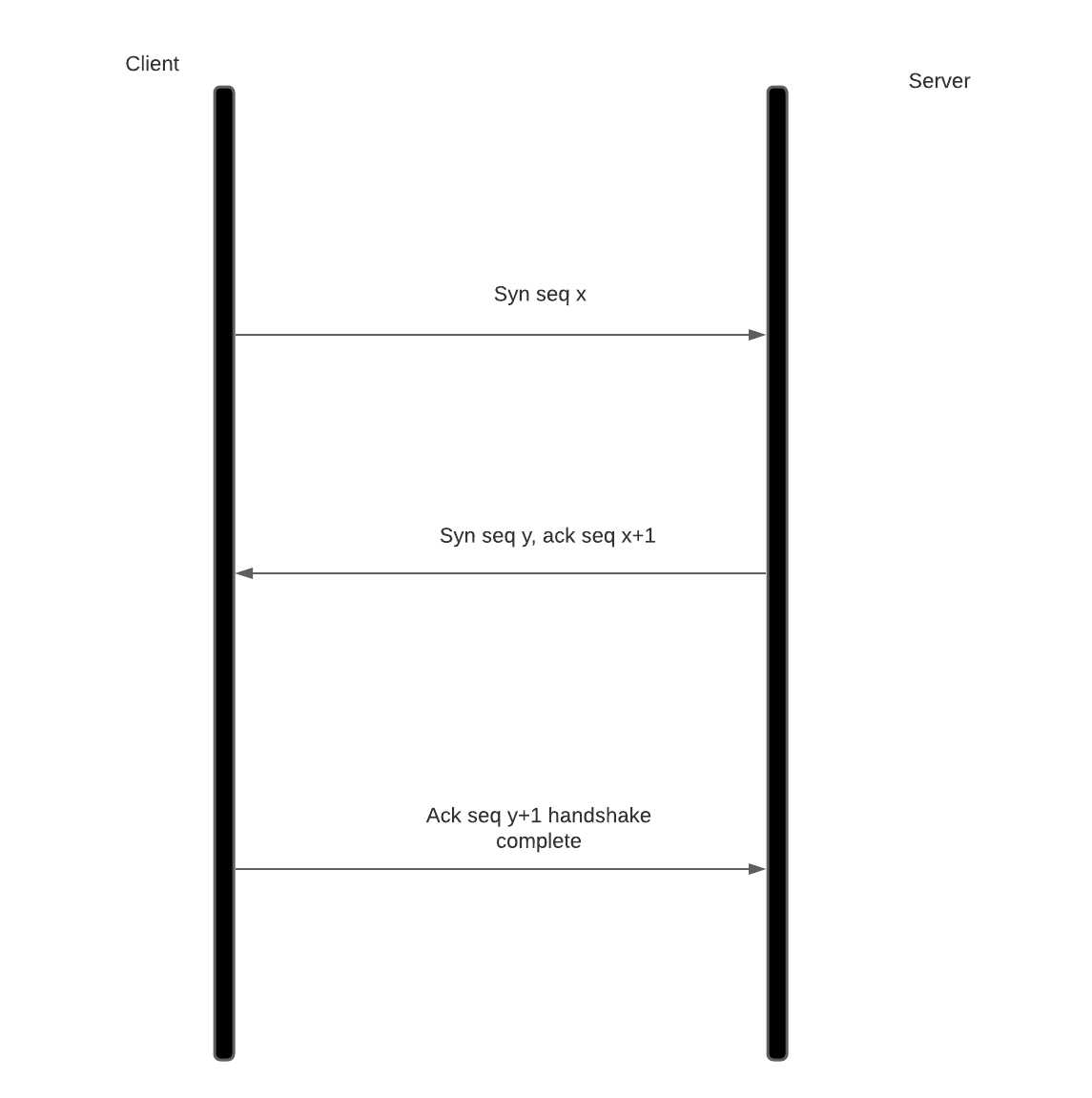
TCP guarantees reliable delivery by using sequence numbers. A TCP connection is established by a three-way handshake. In our case, the client sends a SYN packet along with the starting sequence number it plans to use, the server acknowledges the SYN packet and sends a SYN with its sequence number. Once the client acknowledges the SYN packet, the connection is established. Each data transferred from here on is considered delivered reliably once acknowledgement for that sequence is received by the concerned party.
# To understand handshake run packet capture on one bash session
tcpdump -S -i any port 80
# Run curl on one bash session
curl www.linkedin.com
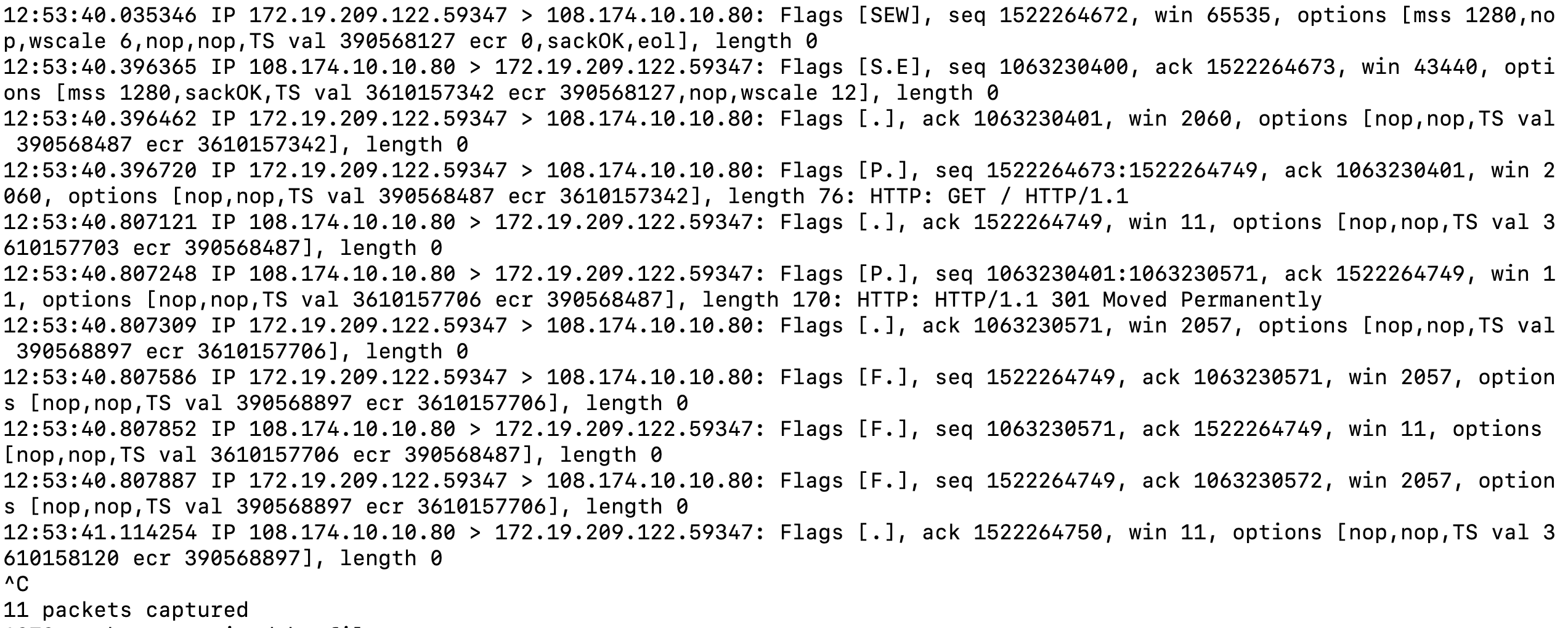
Here, client sends a SYN flag shown by [S] flag with a sequence number 1522264672. The server acknowledges receipt of SYN with an ACK [.] flag and a SYN flag for its sequence number [S]. The server uses the sequence number 1063230400 and acknowledges the client it's expecting sequence number 1522264673 (client sequence + 1). Client sends a zero length acknowledgement packet to the server (server sequence + 1) and connection stands established. This is called three way handshake. The client sends a 76 bytes length packet after this and increments its sequence number by 76. Server sends a 170 byte response and closes the connection. This was the difference we were talking about between HTTP/1.1 and HTTP/1.0. In HTTP/1.1, this same connection can be reused which reduces overhead of three-way handshake for each HTTP request. If a packet is missed between client and server, server won’t send an ACK to the client and client would retry sending the packet till the ACK is received. This guarantees reliability.
The flow control is established by the WIN size field in each segment. The WIN size says available TCP buffer length in the kernel which can be used to buffer received segments. A size 0 means the receiver has a lot of lag to catch from its socket buffer and the sender has to pause sending packets so that receiver can cope up. This flow control protects from slow receiver and fast sender problem.
TCP also does congestion control which determines how many segments can be in transit without an ACK. Linux provides us the ability to configure algorithms for congestion control which we are not covering here.
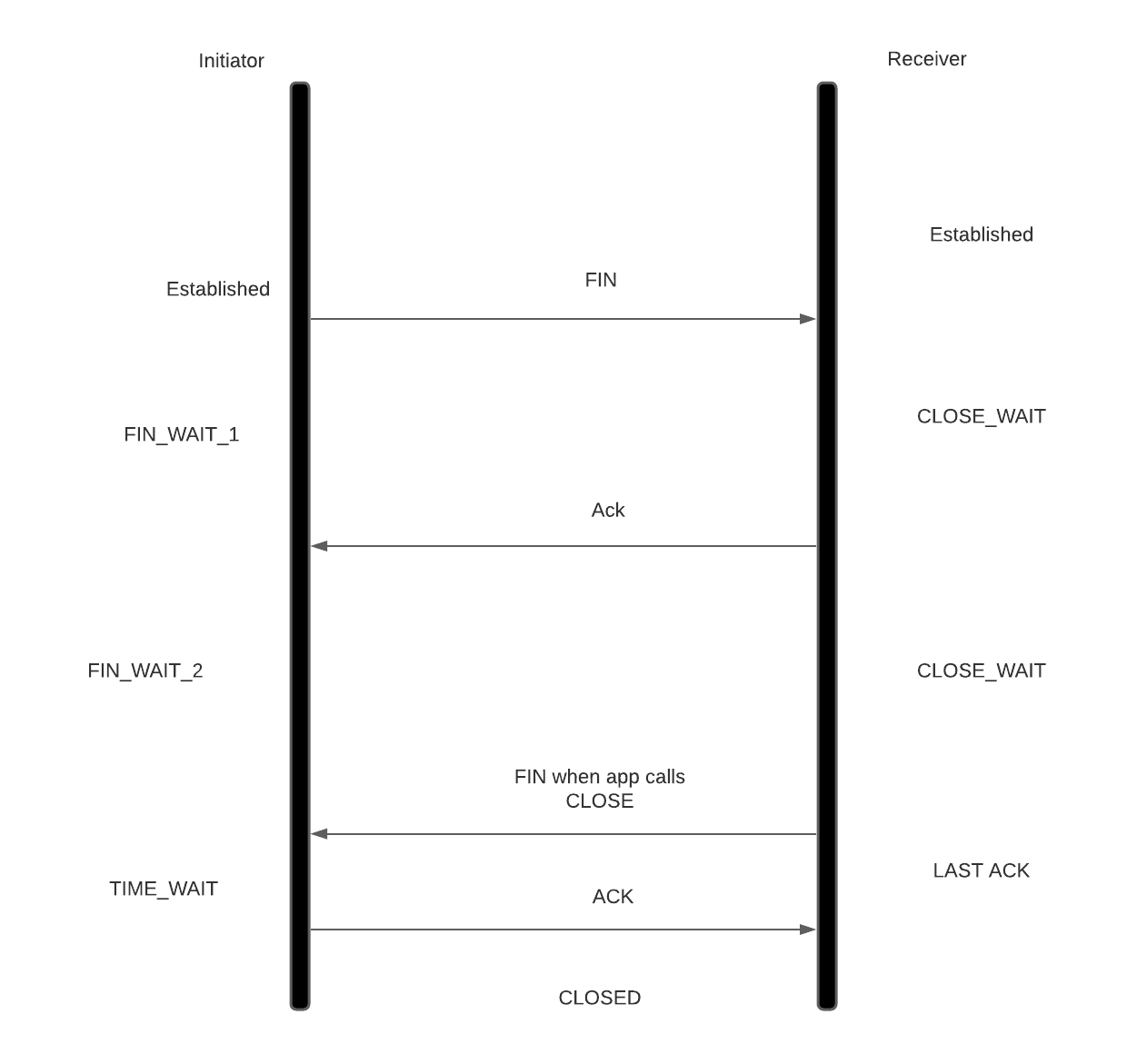
While closing a connection, client/server calls a close syscall. Let's assume client do that. Client’s kernel will send a FIN packet to the server. Server’s kernel can’t close the connection till the close syscall is called by the server application. Once server app calls close, server also sends a FIN packet and client enters into TIME_WAIT state for 2*MSS (120s) so that this socket can’t be reused for that time period to prevent any TCP state corruptions due to stray stale packets.
Armed with our TCP and HTTP knowledge, let's see how this is used by SREs in their role.
Applications in SRE role
- Scaling HTTP performance using load balancers need consistent knowledge about both TCP and HTTP. There are different kinds of load balancing like L4, L7 load balancing, Direct Server Return etc. HTTPs offloading can be done on Load balancer or directly on servers based on the performance and compliance needs.
- Tweaking
sysctlvariables forrmemandwmemlike we did for UDP can improve throughput of sender and receiver. sysctlvariabletcp_max_syn_backlogand socket variablesomax_conndetermines how many connections for which the kernel can complete 3-way handshake before app calling accept syscall. This is much useful in single-threaded applications. Once the backlog is full, new connections stay inSYN_RCVDstate (when you runnetstat) till the application calls accept syscall.- Apps can run out of file descriptors if there are too many short-lived connections. Digging through tcp_reuse and tcp_recycle can help reduce time spent in the
TIME_WAITstate (it has its own risk). Making apps reuse a pool of connections instead of creating ad hoc connection can also help. - Understanding performance bottlenecks by seeing metrics and classifying whether it's a problem in App or network side. Example too many sockets in
CLOSE_WAITstate is a problem on application whereas retransmissions can be a problem more on network or on OS stack than the application itself. Understanding the fundamentals can help us narrow down where the bottleneck is.