RTT
Latency plays a key role in determining the overall performance of the distributed service/application, where calls are made between hosts to serve the users.
RTT is a measure of time, it takes for a packet to reach B from A, and return to A. It is measured in milliseconds. This measure plays a role in determining the performance of the services. Its impact is seen in calls made between different servers/services, to serve the user, as well as the TCP throughput that can be achieved.
It is fairly common that service makes multiple calls to servers within its cluster or to different services like authentication, logging, database, etc, to respond to each user/client request. These servers can be spread across different cabinets, at times even between different data centres in the same region. Such cases are quite possible in cloud solutions, where the deployment spreads across different sites within a region. As the RTT increases, the response time for each of the calls gets longer and thereby has a cascading effect on the end response being sent to the user.
Relation of RTT and throughput
RTT is inversely proportional to the TCP throughput. As RTT increases, it reduces the TCP throughput, just like packet loss. Below is a formula to estimate the TCP throughput, based on TCP mss, RTT and packet loss.
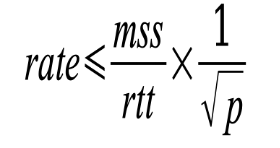
As within a data centre, these calculations are also, important for communication over the internet, where a client can connect to the DC hosted services, over different telco networks and the RTT is not very stable, due to the unpredictability of the Internet routing policies.