Introduction of Annotation Processor
This page introduces a generic schema annotation processing tool in Rest.li. Before reading this, it is recommended that readers be familiar with the concept of PathSpec in Rest.li.
Annotating Pegasus Schemas
In Rest.li, schema authors are able to add annotations using ‘@’ sytnax to schema fields or the schema itself.
Example: annotate on the schema fields
record UserPersonallyIdentifiableInformation {
@data_classification = "MEDIUM"
firstName: string,
@data_classification = "MEDIUM"
lastName: string,
@data_classification = "LOW"
userId: long,
@data_classification = "HIGH"
socialSecurityNumber: string,
}
Example: annotate directly on the schema
@data_classification = "HIGH"
record UserPersonallyIdentifiableInformation {
firstName: string,
lastName: string,
userId: long,
socialSecurityNumber: string,
}
Note that the “data_classifcation” annotation is specified at record level.
These annotations in above examples are stored as an attribute inside DataSchema’s class as “property”. Just as the example shows, both the field and the DataSchema can have this “property”. Rest.li framework did not provide specification on how these annotations should be interpreted and it was left to the user to add logic for interpreting them.
Inherit and override schema annotations
Rest.li users found it useful to process annotations during schema processing. One use case is to introduce “inheritance” and “overrides” to annotations so those annotations can be dynamically processed in the way user defines when the schemas were reused. This gives annotation extensibility and adds to schema reusability.
Here are examples:
Example case 1 : Users might want the annotation of a field to be inherited. The fields can inherit the annotations from the upper level.
@persistencePolicyInDays = 30
record UserVisitRecord {
visitedUrls: array[URL]
visitedUserProfiles: array[UserRecord]
}
Reading from the schema, we might find both visitedUrls and visitedUserProfiles have persistencePolicyInDays annotated as 30.
Example case 2: Users might want the annotation of a field to be overriden. Override is where the annotation on a field or a schema might get updated when other annotations assign it another value.
@persistencePolicyInDays = 30
record UserVisitRecord {
@persistencePolicyInDays = 10
visitedUrls: array[URL]
visitedUserProfiles: array[UserRecord]
}
Reading from the schema, a user might find the field visitedUserProfiless persistencePolicyInDays annotation is 30 but visitedUrls’s persistencePolicyInDays annotation has value 10, which overrides the original value inherited (i.e. the value 30).
Example case 3: Override might also happen when the annotation needs to be updated by another value assigned from other annotation locations
record UserVisitRecord {
//...
@persistencePolicyInDays = 365
recycledChatHistories: array[chat]
@persistencePolicyInDays = 10
visitedUrls: array[URL]
//...
}
record EnterpriseUserRecord {
userName: UserName
//...
@persistencePolicyInDays = {"/recycledChatHistories" : 3650}
visitRecord: UserVisitRecord
//...
}
In this example, the schema EnterpriseUserRecord reused UserVisitRecord and its annotation in the field visitRecord, and overrides the annotation value for the field recycledChatHistories.
All above examples shows that inheritance and overrides give more extensibility to schema annotations. Users should be free to define their own rules regarding how those annotations are read. There should be an unambiguous annotation value for the fields after the user’s rules are applied. The processing step to figure out the eventual value of a field or schema’s annotation is called “resolution” and such value is called “resolved” value.
What is more, users could have their own customized logic to process the annotations and define the custom behavior when annotations are overridden or inherited, and even have the flexibility to set a customized resolved value by calling another local function or remote procedure. The need for such extensibility gives the motivation for Annotation Processor. We aim to build a tool that can process annotations during schema resolution, process all interested annotations by plugging in the user’s own logic and saving the “resolved” value back to the corresponding DataSchema.
A common application of overriding annotation using PathSpec
In the above EnterpriseUserRecord example, @persistencePolicyInDays = {"/recycledChatHistories" : 3650} were used to denote the field that are being overriden is recycledChatHistories. This is basically using PathSpec as a reference to the field or child schema that needs to be overriden. PathSpec can be used as a path to define relationships between fields among nested schemas. Users can use PathSpec to unambiguously specify all the paths to child fields that they want to override.
The above usage is very common at LinkedIn so an implementation of annotation processing based on this behavior is provided as part of annotation processor.
It assumes
(1) All overrides to the fields are specified using PathSpecs to the fields.
(2) All overrides are pointing to fields, and not to the record.
For more examples regarding the syntax, one can read the java doc from PathSpecBasedSchemaAnnotationVisitor, schema processor tests and schema test examples using PathSpec based overriding.
Users can seek to extend this case to adapt to their own use cases. Please see next section regarding what class to extend to fit the best use cases.
Use the schema annotation processor
We have created a paradigm of processing Rest.li schema annotations and wrapped them into com.linkedin.data.schema.annotation package.
First thing to understand is how DataSchema object is internally stored. We added resolvedProperties attribute, in order to store the final resolved annotation.
For an example schema:
record Employee {
id: long
supervisor: Employee
}
Its memory presentation is as followed:
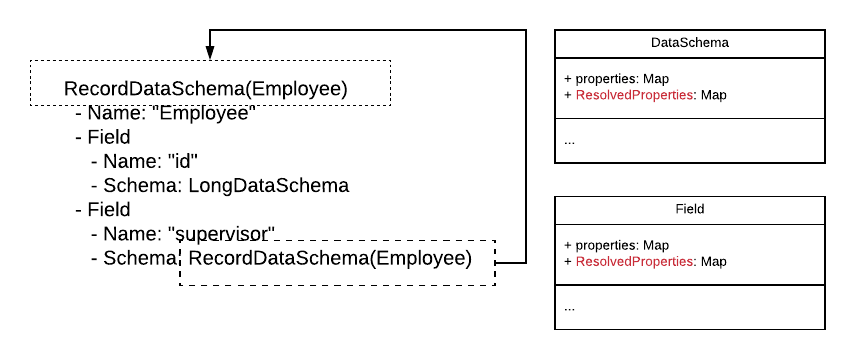
The SchemaAnnotationProcessor will process DataSchema using DataSchemaRichContextTraverser and resolve the annotation for fields in the schemas.
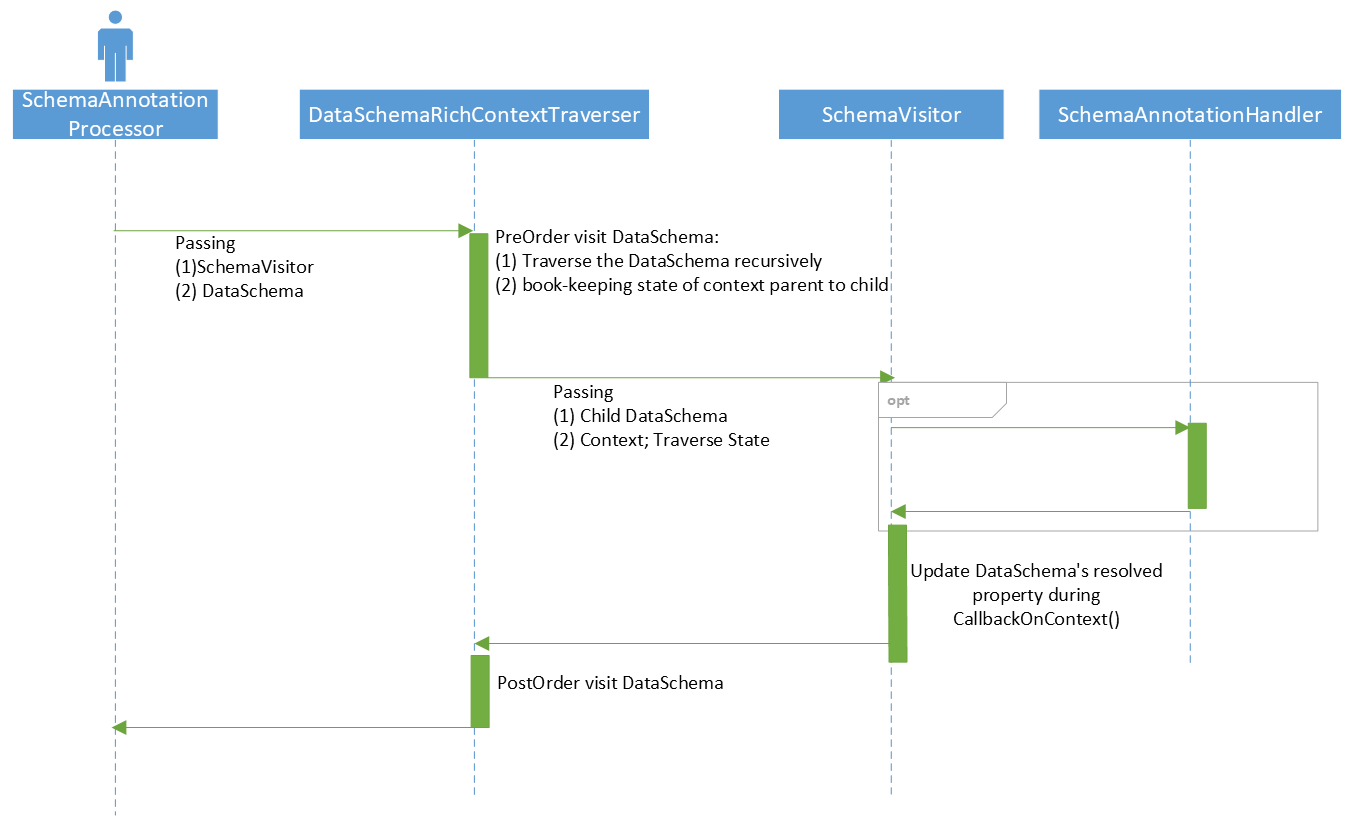
The DataSchemaRichContextTraverser traverse the data schema and in turn calls an implementation of SchemaVisitor. It is the SchemaVisitor that resolves the annotations for fields in the schemas, based on the context provided by the DataSchemaRichContextTraverser. This process would eventually produces a copy of the origianl schema to return, because the original schema should not be modified during traversal.
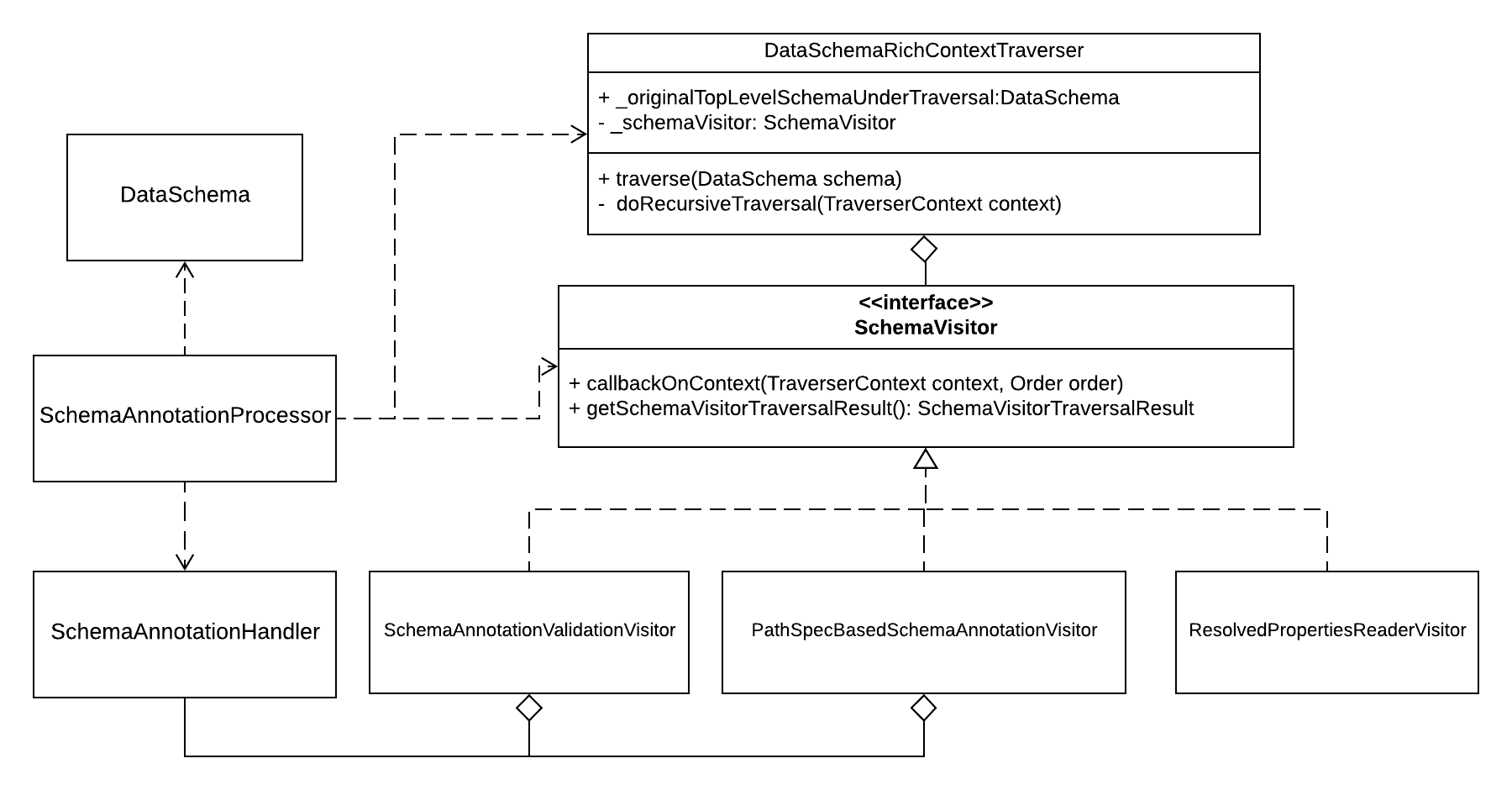
If the overriding of annotations is specified using the PathSpec syntax, the PathSpecBasedSchemaAnnotationVisitor and SchemaAnnotationHandler class are the ones to use for such use case. If a user wants to customize this, one should either look for re-implementing the SchemaVisitor, or extending PathSpecBasedSchemaAnnotationVisitor, or simply implement SchemaAnnotationHandler
| Situation | Recommendation |
|---|---|
| Annotation based on PathSpec based overriding | Create a SchemaAnnotationHandler of your own implementation |
| Annotation based on PathSpec with custom traversal context handling | Override PathSpecBasedSchemaAnnotationVisitor and optionally create a SchemaAnnotationHandler of your own implementation |
| Annotation not using PathSpec based overriding | Implement your own SchemaVisitor |
| Annotation needs custom way of traversal | Override DataSchemaRichContextTraverser |