Dynamic Discovery (D2)
Contents
What is D2
Dynamic Discovery (D2) is a layer of indirection similar to DNS for the rest.li framework. Functionally speaking, D2 translates a URI like d2://<my d2 service> to another address like http://myD2service.something.com:9520/someContextPath.
Rest.li uses D2 to help decouple a REST resource from the real address of the resource. D2 also acts as a client side load balancer.
Note that D2 is an optional layer in the rest.li framework. In fact, rest.li client can communicate directly to rest.li servers without D2. But D2 provides nice benefits like partitioning, load balancing, and many others. Vice versa, D2 can also be used outside of the rest.li framework. Because in essence D2 is just a name service and a load balancer.
If you just need a quick working tutorial for D2 please refer to Dynamic Discovery Quickstart
Terminology
- Service: Represents a REST resource, an endpoint, a thing that you want to interact with. The name of a service must be unique.
- Cluster: Represents a set of Services. A service must belong to exactly one cluster only.
- URI: Represent a machine that belongs to a cluster. A physical representation of a cluster.
As we said above, D2 works like DNS. It translates a D2 URI to a real address. D2 works by keeping the state in Zookeeper. We chose Zookeeper because it's distributed and fault tolerant.
When a client is about to send a request, the D2 client library extract the service name from the d2 URI. Then the d2 client library queries zookeeper for the cluster that owns that service. Once d2 client know the cluster, it will then queries zookeeper for the available URIs for that cluster. Given a list of URIs, D2 client can select which URI to send the request to. The D2 client will listen for any updates related to the cluster and service it previously contacted. So if there's any changes happening either because the server membership changes, or there are new services in a cluster, the d2 client can pick up the changes immediately
Sometimes D2 client's connection to zookeeper might be interrupted. When this happens, D2 will not know what is the latest state so it will assume the state is the same as before. D2 keep backup of the state in the filesystem. If the zookeeper connection interruption happened for a long period of time (configurable), D2 will discard the state and will fail to work.
D2 and Zookeeper
Running D2 requires a Zookeeper ensemble running somewhere. Please download Zookeeper if you don't have one yet.
D2 Load Balancer
As we said above, all the load balancing happened in the client side. D2 client keep tracks of the health of the cluster.
There are 2 types of mode that we can use to load balance traffic.
- Shifting traffic away from one server to the other a.k.a LOAD_BALANCING
- Dropping request on the floor a.k.a CALL_DROPPING.
We aim to alternate between these 2 modes but it’s not always guaranteed.
So how do we choose between CALL_DROPPING and LOAD_BALANCING?
We measure 2 different things for health. One is the cluster health and the other one is the client health.
For cluster health, we only measure the average cluster latency. If the average cluster latency is higher than LoadBalancer’s high water mark, we’ll increment the drop rate by 20%. Drop rate means all traffic to this cluster will be dropped 20% of the time. So obviously cluster health is relevant only to CALL_DROPPING mode. If the cluster latency exceeds high water mark 5 times in a row, we’ll reach 100% drop rate. We have some measure of “recovery mode” to prevent the cluster from getting stuck in perpetual “drop everything” mode. During this mode, we’ll still allow traffic to pass by to calibrate our cluster latency once in a while.
On the other hand, client health is tracked per client. We tracked many things per client e.g. error rate, number of calls, latency of calls, etc. We use this measurement to compute the “computed drop rate” of the client. Healthy client is a client whose latency is lower than client’s high water mark (NOTE that there’s client’s high water mark and there’s also load balancer’s high water mark). For healthy client the computed drop rate should be 0. The computed drop is inversely proportional to the number of virtual points the client gets in a hash ring.
The points are used to distribute traffic amongst many clients. For example there are 4 clients for service “widget”. In perfect condition, each client would have 100 points (this is configurable in service properties). So total points in the hash ring would be 400. If one client’s latency becomes higher than water mark, the computed drop rate will change then the number of points of that client maybe reduced to 80. So that client will receive less traffic and the other servers will get the remaining traffic.
We try to alternate between CALL_DROPPING and LOAD_BALANCING mode. The logic for doing this alternation happens in Load Balancer Strategy.
Implementation of the client load balancer
Here are the moving components that you should know about load balancer:
- Properties (ServiceProperties, ClusterProperties and URIProperties). For load balancing purposes we only care about ServiceProperties. Because that's where all the important parameters, like percent error rate, minimum call count, average latency that we can configure to tell whether a service is in "bad state", are located.
- Clients: rest.li client wraps a client (which we know is a d2 client). The implementation of that client is called DynamicClient. DynamicClient has a LoadBalancer and a wrapper over many simpler R2 clients to send requests.
- LoadBalancer: LoadBalancer figures out the following question: "given a resource name, tell me who can serve the resource, then get all the clients that can send bytes to the servers, then choose one according to the load balancer strategy logic".
- LoadBalancerStrategies: The strategy is used by LoadBalancer to pick one client among many potential clients. The interface takes a list of TrackerClients and choose one to return.
In the following section we’ll elaborate more of each component:
Properties
D2 uses a hierarchy of properties to model the system:
- ServiceProperties
- ClusterProperties
- UriProperties
ServiceProperties
Like its name, ServiceProperties defines anything related to a service. The most important one is the load balancer strategy properties. For example: we can set the highWaterMark and lowWaterMark for this service. If the average latency of all the servers that serves this resource is higher than highWaterMark we’ll start dropping calls because we know the servers are in a “degraded” state.
ClusterProperties
ClusterProperties define’s a cluster’s name, partioning, preferred schemes, banned nodes, and connection properties.
- The schemes are defined in their priority. That is, if a cluster supports both HTTP and Spring RPC, for instance, the order of the schemes defines in which order the load balancer will try to find a client.
- The banned nodes are a list of nodes (URIs) that belong to the cluster, but should not be called.
- The connection properties describe things like what is the maximum size of a response. What is the time out value of an http connection and so on. (Note that we are migrating connection properties to ServiceProperties. This allows users to have a more fine-grained configuration. We estimate the code change will be released in version 1.8.13 and above)
UriProperties
UriProperties define a cluster name and asset of URIs associated with the cluster. Each URI is also given a weight, which will be passed to the load balancer strategy.
D2 Client: what are D2 Client anyway?
D2 Client is a wrapper over other simpler clients. The real implementation of D2 Client is DynamicClient.java. But underneath we use R2 client to shove bits from client to server. So DynamicClient wraps r2 clients with three classes: TrackerClient, RewriteClient, and LazyClient. The underlying R2 clients are: HttpNettyClient, FilterChainClient and FactoryClient.
TrackerClient
The TrackerClient attaches a CallTracker and Degrader to a URI. When a call is made to this client, it will use call tracker to track it, and then forward all calls to the r2 client. CallTracker keeps track of call statistics like call count, error count, latency, etc.
RewriteClient
The RewriteClient simply rewrites URIs from the URN style to a URL style. For example, it will rewrite “urn:MyService:/getWidget” to “http://hostname:port/my-service/widgets/getWidget”.
LazyClient
The LazyClient is just a wrapper that does not actually create an r2 client until the first rest/rpc request is made.
Client Wrapper Diagram
LoadBalancer
There is currently one “true” implementation of a LoadBalancer in com.linkedin.d2.balancer. This implementation is called SimpleLoadBalancer. There are other implementations of LoadBalancer that will wrap this SimpleLoadBalancer for example: ZKFSLoadBalancer. In any case, the simple load balancer contains one important method: getClient. The getClient method is called with a URN such as “urn:MyService:/getWidget”. The responsibility of the load balancer is to return a client that can handle the request, if one is available, or to throw a ServiceUnavailableException, if no client is available.
When getClient is called on the simple load balancer, it: <ul> <li>First tries to extract the service name from the URI that was provided. </li> <li> It then makes sure that it’s listening to that service in the LoadBalancerState. </li> <li> It then makes sure that it’s listening to the service’s cluster in the LoadBalancerState </li> <li> If either the service or cluster is unknown, it will throw a ServiceUnavailableException. </li> <li> It will then iterate through the prioritized schemes (prpc, http, etc) for the cluster. </li> <li> For each scheme, it will get all URIs in the service’s cluster for that scheme, and ask the service’s load balancer strategy to load balance them.</li> <li> If the load balancer strategy returns a client, it will be returned, otherwise the next scheme will be tried.</li> <li>If all schemes are exhausted, and no client was found, a ServiceUnavailableException will be thrown. </li> </ul>
Strategies
Load balancer strategies have one responsibility. Given a list of TrackerClients for a cluster, return one that can be used to make a service call. There are currently two implementations of load balancer strategies: random and degrader.
Random
The random load balancer strategy simply chooses a random tracker client from the list that it is given. If the list is empty, it returns null. This is the default behavior for dev environment. Because in development environments, one may wish to use the same machine for every service. so with this strategy, we will always return the “dev” tracker client to route the request (and prevent confusion).
Degrader
The load balancer strategy that attempts to do degradation is the DegraderLoadBalancerStrategy. Here are some facts about the degrader strategy: <ul>
Partitioning
D2 currently support range-based and hash-based partitioning.
Load Balancer Flow
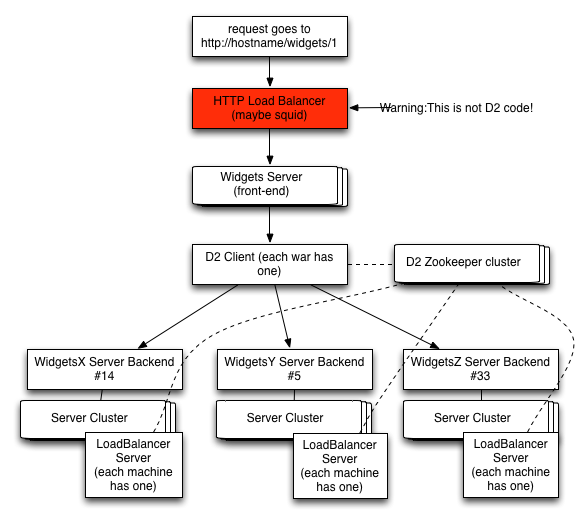
Here is an example of the code flow when a request comes in. For the sake of this example, we’ll a fictional widget service. Let’s also say that in order to get the data for a widget resource, we need to contact 3 different services: WidgetX, WidgetY, and WidgetZ backend.
On the server side:
On the client side:
Stores
In D2, a store is a way to get/put/delete properties.
Store Type
ZooKeeper
D2 contains two ZooKeeper implementations of DynamicDiscovery. The first is the ZooKeeperPermanentStore. This store operates by attaching listeners to a file in ZooKeeper. Every time the file is updated, the listeners are notified of the property change. The second is the ZooKeeperEphemeralStore. This store operates by attaching listeners to a ZooKeeper directory, and putting sequential ephemeral nodes inside of the directory. The ZooKeeperEphemeralStore is provided with a “merger” that merges all ephemeral nodes into a single property. Whenever a node is added or removed to the directory, the ZooKeeperEphemeralStore re-merges all nodes in the directory, and sends them to all listeners.
In the software load balancing system, the permanent store is used for cluster and service properties, while the ephemeral store is used for URI properties.
File System
The file system implementation simply uses a directory on the local filesystem to manage property updates. When a property is updated, a file is written to disk with the property’s key. For instance, putting a property with name “foo” would create /file/system/path/foo, and store the serialized property data in it. The File System will then alert all listeners of the update.
In-Memory
The in-memory implementation of Dynamic Discovery just uses a HashMap to store properties by key. Whenever a store is put/delete occurs, the HashMap is updated, and the listeners are notified.
Toggling
The toggling store that wraps another PropertyStore. The purpose of the toggling store is to allow a store to be “toggled off”. By toggling a store off, all future put/get/removes will be ignored. The reason that this class is useful is because LinkedIn wants to toggle the ZooKeeper stores off if connectivity is lost with the ZooKeeperCluster (until a human being can verify the state of the cluster, and re-enable connectivity).
Registries
In D2, a registry is a way to listen for properties. Registries allow you to register/unregister on a given channel. Most stores also implement the registry interface. Thus, if you’re interested in updates for a given channel, you would register with the store, and every time a put/delete is made, the store will update the listeners for that channel.
Messengers
By default, none of the stores in Dynamic Discovery are thread safe. To make the stores thread safe, a PropertyStoreMessenger can be used. The messenger is basically a wrapper around a store that forces all writes to go through a single thread. Reads still happen synchronously.
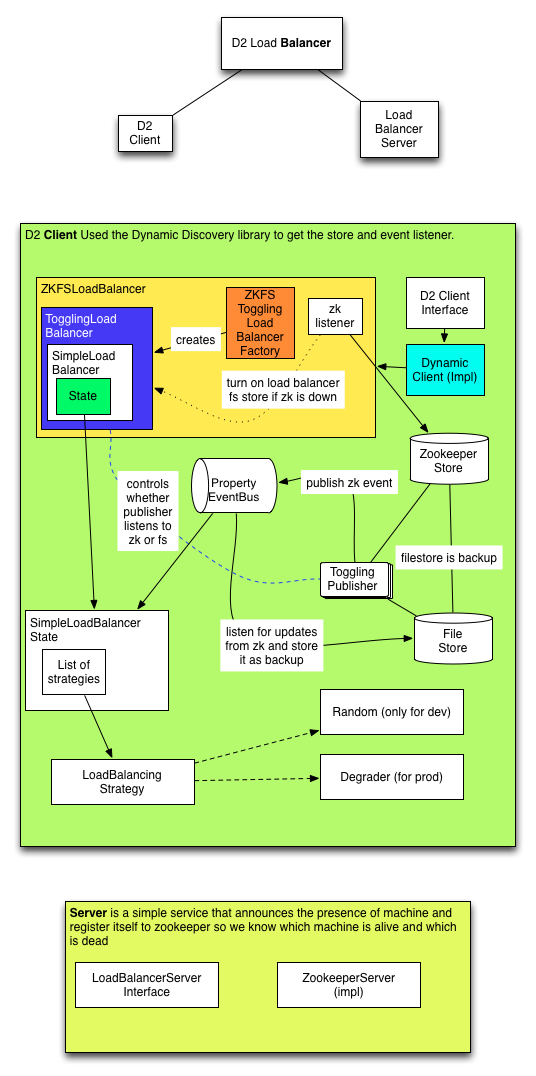
Operations
Populating Zookeeper
Deleting zookeeper nodes
JMX
We have beans in the com.linkedin.d2 JMX name space.