Liger Kernel: Efficient Triton Kernels for LLM Training¶
| Stable | Nightly | Discord | Build | ||
|---|---|---|---|---|---|
|
|

|
|

|
|
|
![]()
Liger Kernel is a collection of Triton kernels designed specifically for LLM training. It can effectively increase multi-GPU training throughput by 20% and reduces memory usage by 60%. We have implemented Hugging Face Compatible RMSNorm, RoPE, SwiGLU, CrossEntropy, FusedLinearCrossEntropy, and more to come. The kernel works out of the box with Flash Attention, PyTorch FSDP, and Microsoft DeepSpeed. We welcome contributions from the community to gather the best kernels for LLM training.
We've also added optimized Post-Training kernels that deliver up to 80% memory savings for alignment and distillation tasks. We support losses like DPO, CPO, ORPO, SimPO, JSD, and many more. Check out how we optimize the memory.
Supercharge Your Model with Liger Kernel¶
With one line of code, Liger Kernel can increase throughput by more than 20% and reduce memory usage by 60%, thereby enabling longer context lengths, larger batch sizes, and massive vocabularies.
| Speed Up | Memory Reduction |
|---|---|
 |
 |
Note: - Benchmark conditions: LLaMA 3-8B, Batch Size = 8, Data Type =
bf16, Optimizer = AdamW, Gradient Checkpointing = True, Distributed Strategy = FSDP1 on 8 A100s. - Hugging Face models start to OOM at a 4K context length, whereas Hugging Face + Liger Kernel scales up to 16K.
Optimize Post Training with Liger Kernel¶
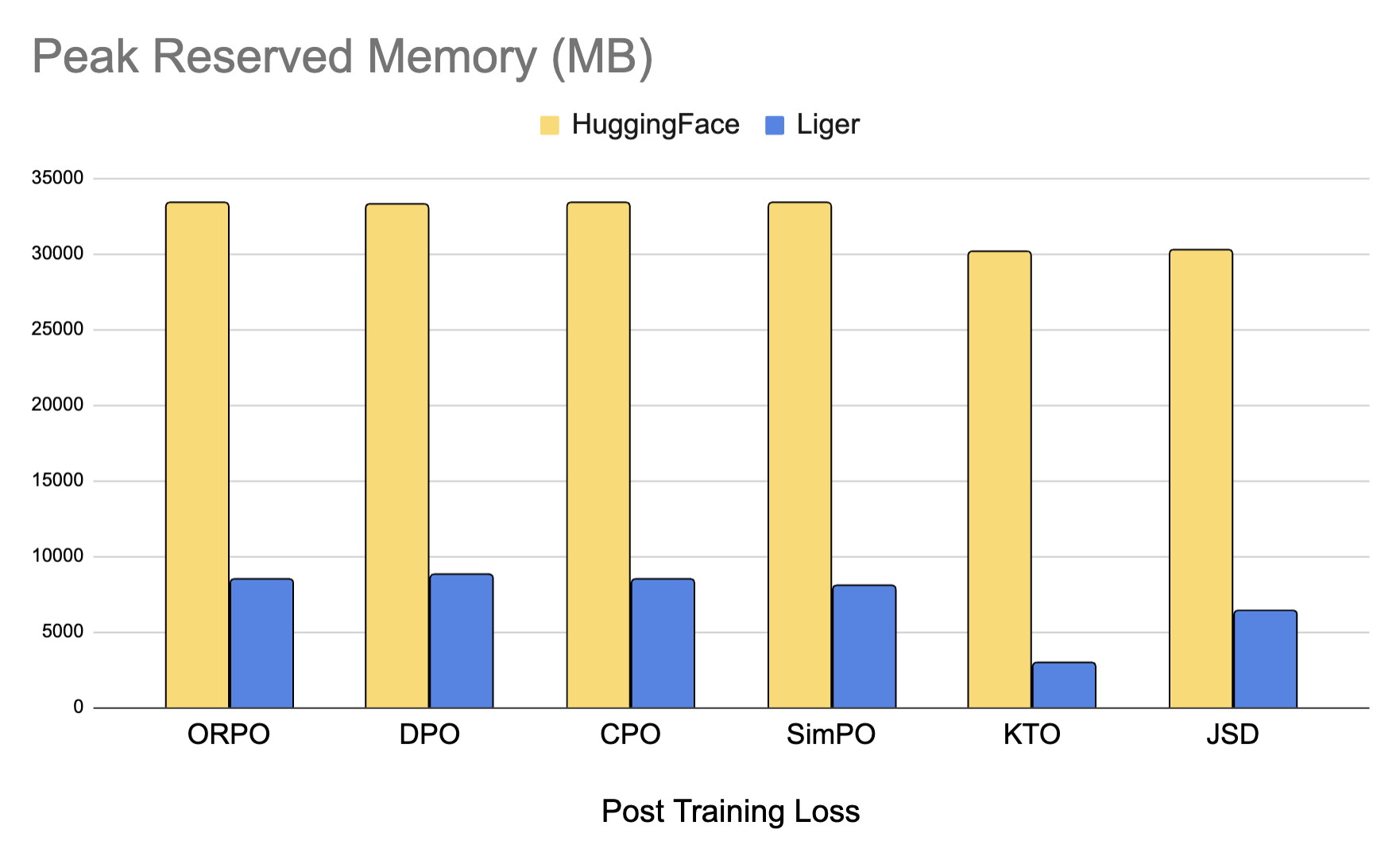
We provide optimized post training kernels like DPO, ORPO, SimPO, and more which can reduce memory usage by up to 80%. You can easily use them as python modules.
from liger_kernel.chunked_loss import LigerFusedLinearDPOLoss
orpo_loss = LigerFusedLinearORPOLoss()
y = orpo_loss(lm_head.weight, x, target)
Key Features¶
- Ease of use: Simply patch your Hugging Face model with one line of code, or compose your own model using our Liger Kernel modules.
- Time and memory efficient: In the same spirit as Flash-Attn, but for layers like RMSNorm, RoPE, SwiGLU, and CrossEntropy! Increases multi-GPU training throughput by 20% and reduces memory usage by 60% with kernel fusion, in-place replacement, and chunking techniques.
- Exact: Computation is exact—no approximations! Both forward and backward passes are implemented with rigorous unit tests and undergo convergence testing against training runs without Liger Kernel to ensure accuracy.
- Lightweight: Liger Kernel has minimal dependencies, requiring only Torch and Triton—no extra libraries needed! Say goodbye to dependency headaches!
- Multi-GPU supported: Compatible with multi-GPU setups (PyTorch FSDP, DeepSpeed, DDP, etc.).
- Trainer Framework Integration: Axolotl, LLaMa-Factory, SFTTrainer, Hugging Face Trainer, SWIFT
Installation¶
To install the stable version:
To install the nightly version:
To install from source:
git clone https://github.com/linkedin/Liger-Kernel.git
cd Liger-Kernel
# Install Default Dependencies
# Setup.py will detect whether you are using AMD or NVIDIA
pip install -e .
# Setup Development Dependencies
pip install -e ".[dev]"
Dependencies
CUDA¶
torch >= 2.1.2triton >= 2.3.0
ROCm¶
torch >= 2.5.0Install according to the instruction in Pytorch official webpage.triton >= 3.0.0Install from pypi. (e.g.pip install triton==3.0.0)
Optional Dependencies
transformers >= 4.x: Required if you plan to use the transformers models patching APIs. The specific model you are working will dictate the minimum version of transformers.
Note
Our kernels inherit the full spectrum of hardware compatibility offered by Triton.
Sponsorship and Collaboration¶
- AMD: Providing AMD GPUs for our AMD CI.
- Intel: Providing Intel GPUs for our Intel CI.
- Modal: Free 3000 credits from GPU MODE IRL for our NVIDIA CI.
- EmbeddedLLM: Making Liger Kernel run fast and stable on AMD.
- HuggingFace: Integrating Liger Kernel into Hugging Face Transformers and TRL.
- Lightning AI: Integrating Liger Kernel into Lightning Thunder.
- Axolotl: Integrating Liger Kernel into Axolotl.
- Llama-Factory: Integrating Liger Kernel into Llama-Factory.
Contact
- For issues, create a Github ticket in this repository .
- For open discussion, join our discord channel .
- For formal collaboration, send an email to byhsu@linkedin.com .
Cite this work¶
Bib Latex entry:
@inproceedings{
hsu2025ligerkernel,
title={Liger-Kernel: Efficient Triton Kernels for {LLM} Training},
author={Pin-Lun Hsu and Yun Dai and Vignesh Kothapalli and Qingquan Song and Shao Tang and Siyu Zhu and Steven Shimizu and Shivam Sahni and Haowen Ning and Yanning Chen and Zhipeng Wang},
booktitle={Championing Open-source DEvelopment in ML Workshop @ ICML25},
year={2025},
url={https://openreview.net/forum?id=36SjAIT42G}
}